

In my last post, A Tale of Two Scaling Laws, we explored the dominant strategies for improving AI performance: scaling model size and scaling inference-time compute—specifically by extending the length of reasoning traces.
Ultimately, we found that the optimal scaling strategy depends on the task:
Is it more knowledge-intensive or reasoning-intensive?
After confirming that performance gains on my spatial reasoning task were more sensitive to improvements in compositional reasoning than to increases in base model size, I began exploring how to get more from test-time compute.
The Problem: Rushed Reasoning in SpaceThinker
My finetuning dataset, SpaceThinker, was designed to train multimodal thinking for enhanced quantitative spatial reasoning in VLMs. It introduced a <think>...</think> wrapper around intermediate reasoning to encourage structured thought at inference time based on reasoning traces grounded in 3D scene graphs.
However, as I tried prompting the model to generate more detailed thoughts, I noticed a subtle failure mode:
The model struggled to generate longer reasoning traces even with long-context capability in the base model and explicit instruction.
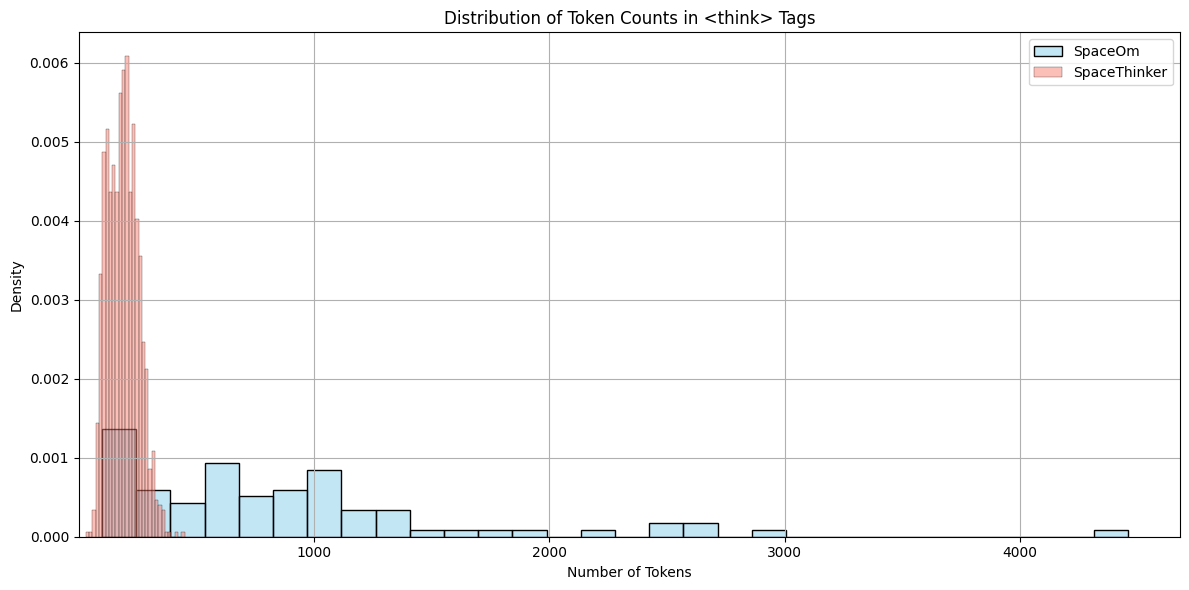
Why? Because SpaceThinker's average <think> section was under 200 tokens. The model had learned to reason briefly and stop. Even models with long context windows become conditioned to use only a fraction of the available thinking budget without exposure to longer traces in training.
This bias becomes a major limiting factor as modulating response length becomes a key lever for enhanced reasoning. Unfortunately, if your training dataset doesn't support longer and more varied reasoning patterns, prompting alone won't suffice.
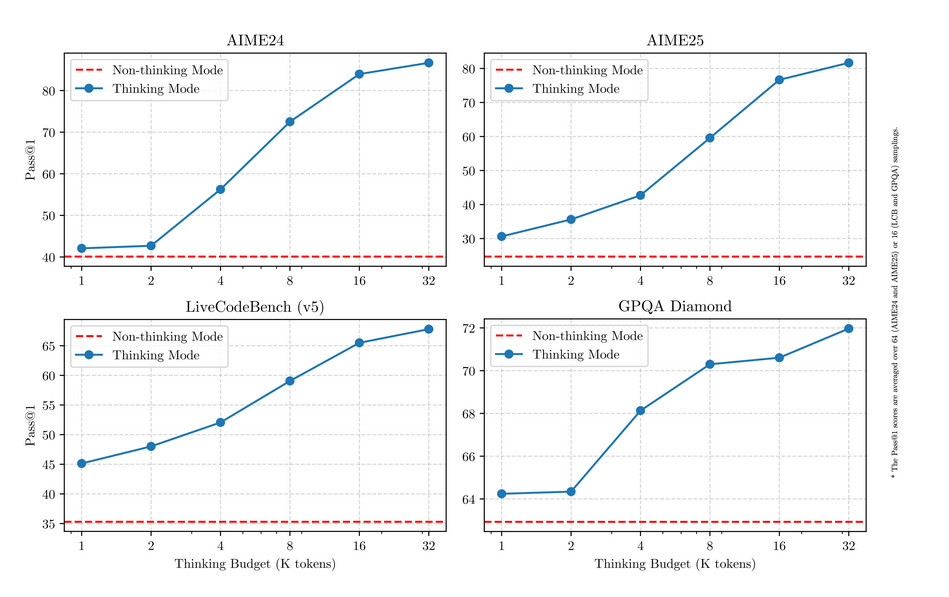
Ideally, we'd like to replicate what Qwen 3 observed:
> Smooth, monotonic gains in reasoning performance as a function of increased test-time compute.
The Fix: SpaceOm and Budget-Aware Thinking
To address this, I created SpaceOm—a new dataset explicitly curated with longer reasoning traces, often ranging from 500 to over 2000 tokens.
Crucially, we designed these examples with user instructions like:
"Explain briefly"
"In about 800 tokens"
"Give me the full breakdown (~3000 words)"
This structure teaches the model not just how to think but how much. In early experiments, SpaceOm-trained models demonstrate:
Structured thoughts over longer spans
Follows user-instructions to modulate thinking budget
What's Next: Thought Control
Now, we're training models to reason elastically—to spend their thinking budget when a task demands it, conserve it when brevity suffices, and adapt under compute constraints.
So the next step is to train a new VLM, capable of both:
Modulating its thinking budget at test time
Toggling reasoning on or off via system prompt cues
We'll do this by combining:
SpaceThinker (brief reasoning)
SpaceOm (long, budget-conditioned thinking)
Converted non-reasoning tasks (e.g., OpenSpaces_MC) with disabled reasoning
🧠 The Mind, Once Stretched
At this point, we're not just making a better model or beating frontier baselines on our task. We're testing a broader hypothesis:
Reasoning budgets are a learned behavior, and the ability to use your thinking budget depends on your experience in spending it.
Reasoning models aren't always the right tool for every job. But the ability to scale compute with complexity—to think harder when it matters—is one of their core advantages.
So here's the question:
Can you afford to reason on a fixed budget?
Check the distribution of reasoning trace lengths in your training data.
It may be time to teach your model to summon the powers of thinking harder by balancing that distribution.