
A Tale of Two Scaling Laws
Why Thinking Harder, Not Smarter Works Well In Reasoning-Intensive Tasks

We're on the cusp of the next significant compute platform shift as AI powers more embodied AI applications, including drones and robotics, in the world around us. However, the AI behind these applications still struggles with fundamental capabilities like 3D scene understanding from image inputs.
What makes AI better at estimating distances between objects in real-world scenes? In the past, the easiest way to improve AI performance relied on one simple strategy: make the model bigger. But our recent findings from evaluating SpaceThinker-Qwen2.5VL-3B on the QSpatial++ benchmark tell a more nuanced story. Read more here.
In this post, we share a case study on quantitative spatial reasoning in light of the two dominant scaling strategies in AI today: increasing model size and increasing test-time compute. What we found is reshaping how we think about scaling for performance, particularly in tasks that require structured, step-by-step reasoning.
The Problem: Estimating Distance from RGB + Natural Language
The QSpatial++ benchmark challenges models to estimate distances or object sizes based on a single RGB image and a natural language prompt. It represents essential reasoning skills needed in robotics and embodied AI, where agents must make judgments in 3D space from 2D images.
Despite the simplicity for humans, this task lies at the frontier of what today's multimodal models can do.
Scaling Law #1: Bigger Models Are Better?
Historically, the most straightforward way to improve performance has been to scale up to the next larger model in the architecture family. Larger architectures can internalize more world knowledge and patterns, crucial for knowledge-heavy tasks (e.g., trivia QA).
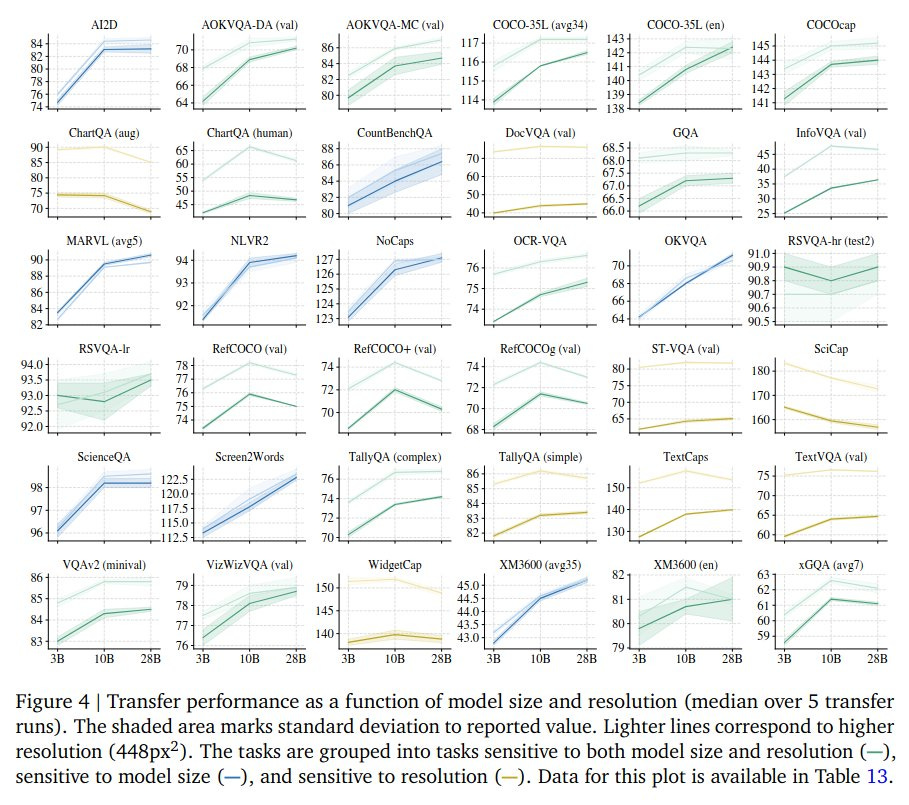
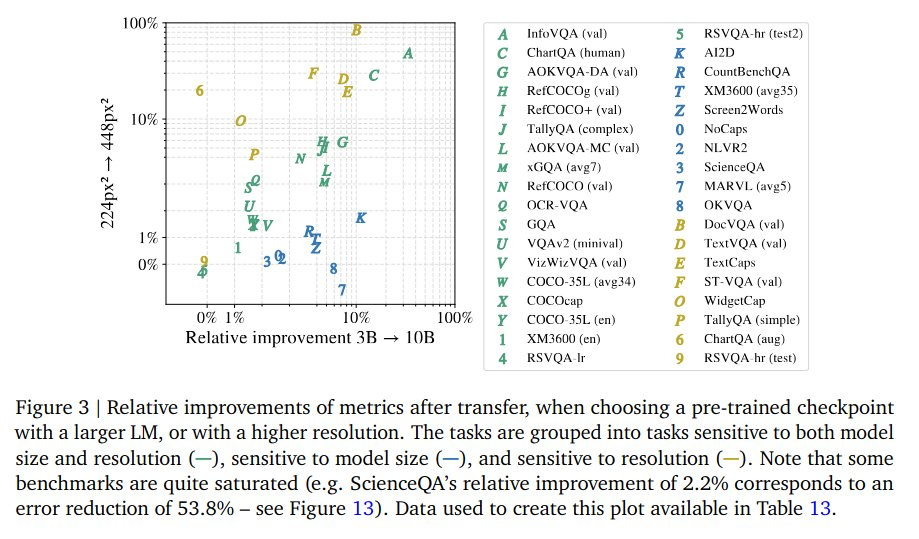
The figures from the Paligemma 2 task transfer and model scaling studies support this narrative up to a point. Most benchmarks show diminishing returns beyond ~10B parameters, and improvements on most tasks tend to be modest (often <10%) when going from 3B to 10B or 28B.
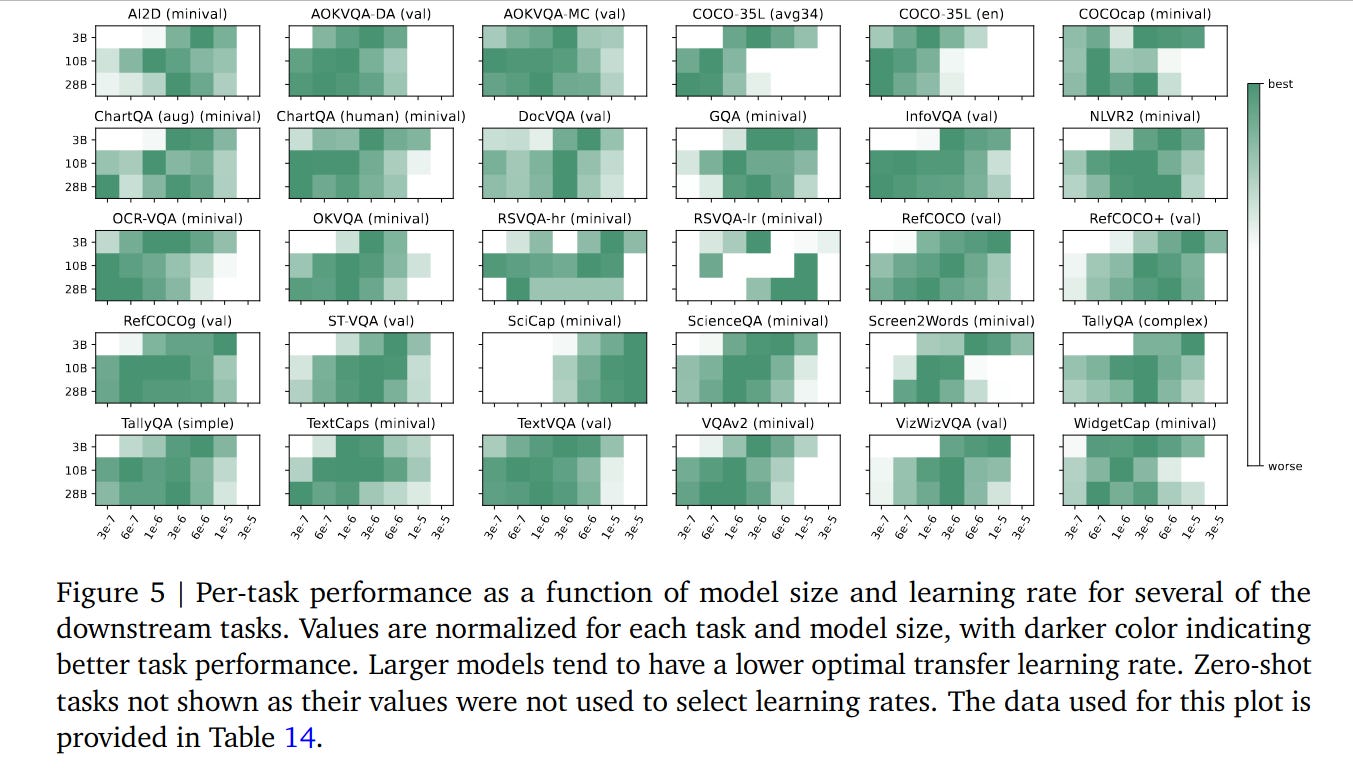
Moreover, though the researchers found that the optimal learning rate consistently decreases as the model size increases, determining the best value for larger models makes fine tuning more costly.
Scaling Law #2: More Thinking at Test Time
Most new AI models are trying to capitalize on a newly emerging scaling law: test-time compute scaling. Instead of making the model larger, we let it think longer. Thinking longer means:
Allocating a larger token budget at inference (e.g., 8K–32K)
Using structured prompts like chain-of-thought (CoT)
The analysis of Qwen 3 research showed that models that allow reasoning with more tokens at inference time performed much better in mathematical reasoning tasks.
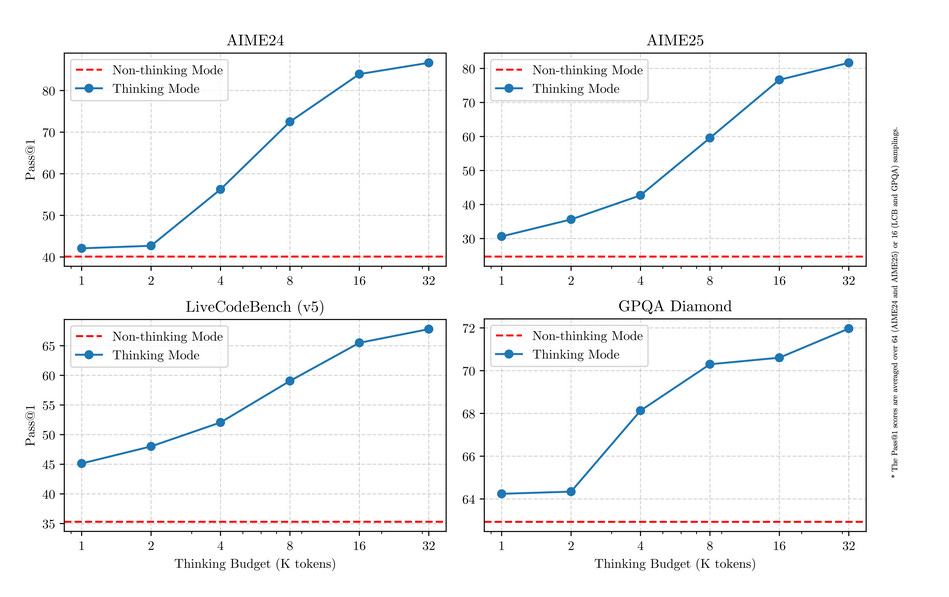
For example, a 3B model with a "thinking budget" of 32K tokens can rival or exceed 10X larger models in reasoning-heavy domains.
Our Findings: Spatial Reasoning Is Compute-Sensitive, Not Memory-Sensitive
Exploring these ideas in the context of improving SpaceThinker, our open 3B model finetuned for spatial tasks, the results were striking:
Performance increased significantly with longer, stepwise reasoning prompts
A non-reasoning variant (SpaceQwen) got worse with CoT-style prompting
The gap between SpaceThinker and closed models like Gemini and GPT-4o shrunk when using step-by-step reasoning with inference-time compute
Strong improvements from CoT prompting 3B reasoning models suggest that spatial reasoning tasks, like distance estimation, are reasoning-intensive, not knowledge-intensive.
In other words, they benefit more from compute spent on step-by-step inference than running models with larger parameter counts.
So, Reasoning Beats Knowledge?
Of course, answering this depends on your task. Your AI may improve most by adopting both scaling strategies so you can access and reason over the world's scientific knowledge.
But for spatial reasoning, our evidence favors test-time compute as the dominant strategy for improvement. Instead of training bigger models, we recommend:
Allocating larger token budgets at inference utilizing CoT reasoning
Training smaller models like SpaceThinker to enhance reasoning priors
This approach is cheaper, more efficient, and better suited to emerging use cases in embodied AI and robotics, which require navigating complex, real-world scenes and planning.
Final Thoughts
It used to be that you could expect consistent improvements to your AI by "just scaling up" the architecture. However, for tasks that require thinking, not just remembering, you'll need to consider another strategy for tasks where deliberation beats memorization.
With the rise of tool-augmented, context-rich AI, developers pushing beyond frontier performance may turn to not the biggest, smartest model but the most thoughtful one.