


Building a Knowledge Flywheel
Don't let your social media feed constrain your AI strategy.

AI innovation outpaces even Twitter. Miss an announcement, and you're set back by months of development time that you can't recover. That's why last week, I shared a simple way to find the most relevant recommendations for your next AI experiment.
⏱️ 4 hours after SpatialScore dropped on arXiv, I added the benchmark to my queue. Here's how my research radar feeds into a knowledge flywheel.
⚡The Recipe for Instant Discovery
🗂️ Feed your project notes & logs
📑 Feed today's arXiv abstracts
🤖 Ask LLM for practical recommendations
These preprint previews aren't just for recommended reading. I've already finished updating the SpatialScore benchmark comparisons to include SpaceThinker. See the extended comparison.
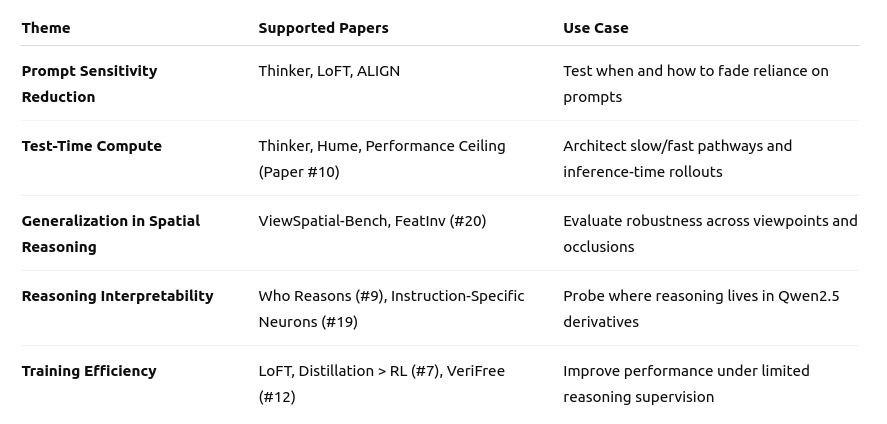
Over the past week, I've identified several new benchmarks to assess SpaceThinker's capabilities and even created datasets to hone them further. I've learned about how specific fine-tuning design choices can impact a model's reasoning capabilities, which will inform follow-up experiments. These findings enable me to move past surface-level correlations and semantic similarities to build insights that transfer robustly.
More concretely, I grouped the experiment results by common factors such as parameter count, model family, reasoning capability, prompting with step-by-step instructions, or fine-tuning protocol. Finally, I ran regressions and causal inference to determine what contributes most to performance in quantitative spatial reasoning. At this point, we're well beyond the literature review, and we're composing and distilling data into knowledge. This AI-powered discovery loop has accelerated my work, even enabling me with new methods for establishing these relationships.
Overall, my analysis highlights the importance of fine-tuning and test-time compute for my application. The evidence supports design choices to further optimize reasoning and de-prioritize sweeps with larger LLM backbones.
Will I observe the gains claimed in research when I swap OpenVision for CLIP in my vision tower? Will more visual tokens from finer image patchification be worth the additional memory overhead? Or are my scenes sufficiently structured, my objects regular enough that I am better off using fewer visual tokens? Exploring these hypotheses brings us closer to reality.

Finally, I recommend the next experiment grounded in the full context of my work, including the results of an empirical and comparative analysis.
You learned it in grade school: Hypothesis → controlled run → observation → refinement — aka scientific method. Insights compound with each iteration of our knowledge flywheel as observations frame the following hypothesis.
With a deeper understanding of the problem's structure, I can more efficiently explore the space of possibilities. Just as learning from the history of experiments guides my selection of what's next, each new question gives rise to data I'll render into new knowledge. By engaging with these inquiries, we refine our hypotheses, grounding what's next on an improved understanding.
The learning loop I'm describing is available to anyone, and you reach a greater learning velocity with a well-designed knowledge flywheel.
What truth are you accelerating toward?