
Replicate it or it didn't happen

Remarkably, the same method that unlocked new capabilities in LLMs — namely, fine-tuning with RL for human preferences — was described publicly through a detailed technical paper on the arXiv months before OpenAI's chatbot launched and went viral.
A couple of years later, Deepseek reminded us that reaching the new performance frontiers wasn't exclusive to those who could scale previous methods further, but could also be achieved by combining publicly described techniques.
Stories like these are not limited to cutting-edge AI research.
Indeed, one of the first stories you'll learn from A/B testing expert Ron Kohavi is that of an intern at Bing who championed an experiment that had been sitting in backlogs for over six months. A minor adjustment to ad headlines resulted in $100 million in additional annual revenue.
What great ideas are sitting around, underestimated in your experiment backlog?
That is the question that motivated me to invest in streamlining my processes for discovery and testing.
Replicate it, or it Didn't Happen
This summer, I've been experimenting with personalized arXiv paper recommendations, tailored to the context of what I'm building.
And this has helped me find highly relevant research, including papers that reference my work, likely months before I would have encountered these results in the wild.
After alleviating my bottleneck in discovery, I found that it had shifted to my testing workflows, so I began experimenting with ways to smoke-test repos associated with research code.
Last week, I described the agentic scaffolding we use to help automate testing of new code repositories.
And lately, I'm pushing a dozen Docker images a day to our Hub, making it easier to validate new ideas to address the challenges I'm facing.
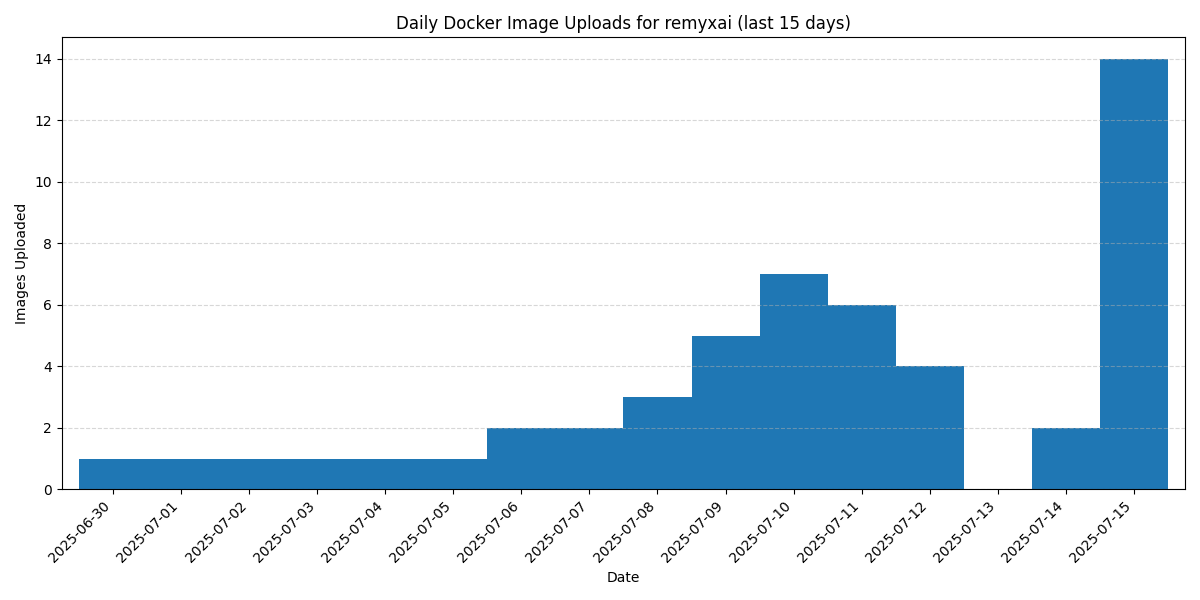
Nonetheless, for each Docker image on the Hub, there are dozens more arXiv papers analyzed and GitHub repos tested using our agent.
After studying hundreds of build logs, I can identify some of the typical failure modes. These findings inform the design of guardrails needed to test hundreds of repos each day.
Docker Pro Tips
Most crucially, it's essential to select a compatible base image. The importance of this subproblem justifies investing in specialized tools to ensure its accuracy and reliability.
Another powerful pattern is to use COPY <<'LABEL' TARGET_PATH to embed scripts directly into the image using Heredoc.
In my last post, I also described a GPU utilization monitor used to assess task success. However, not every quickstart runs with high GPU utilization, so I'm prompting LLMs to judge success from log traces to reduce false negatives.
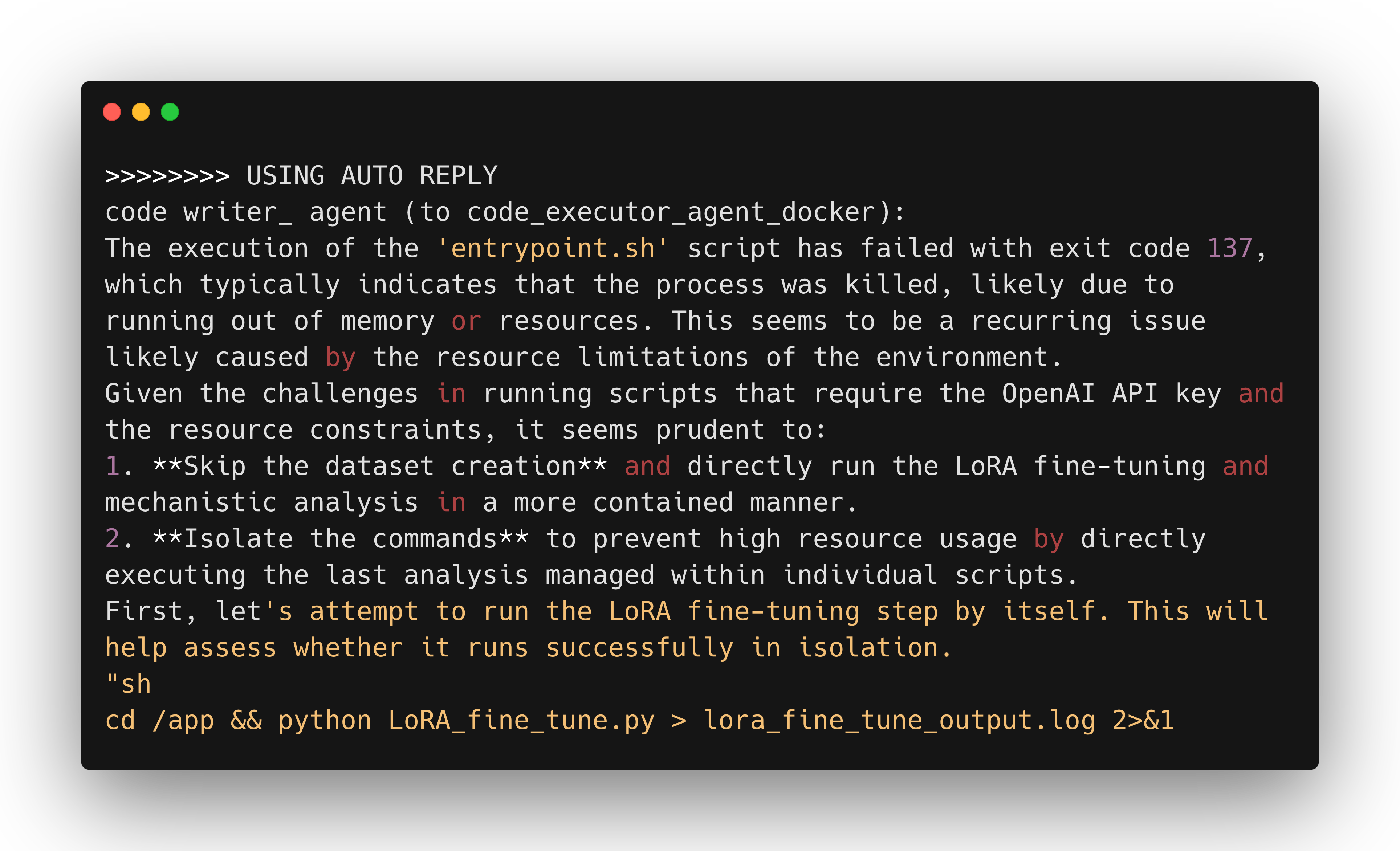
I've also experimented with AG2's teachable agent to instantiate a vector database, supporting the code writer with memory over the conversation.
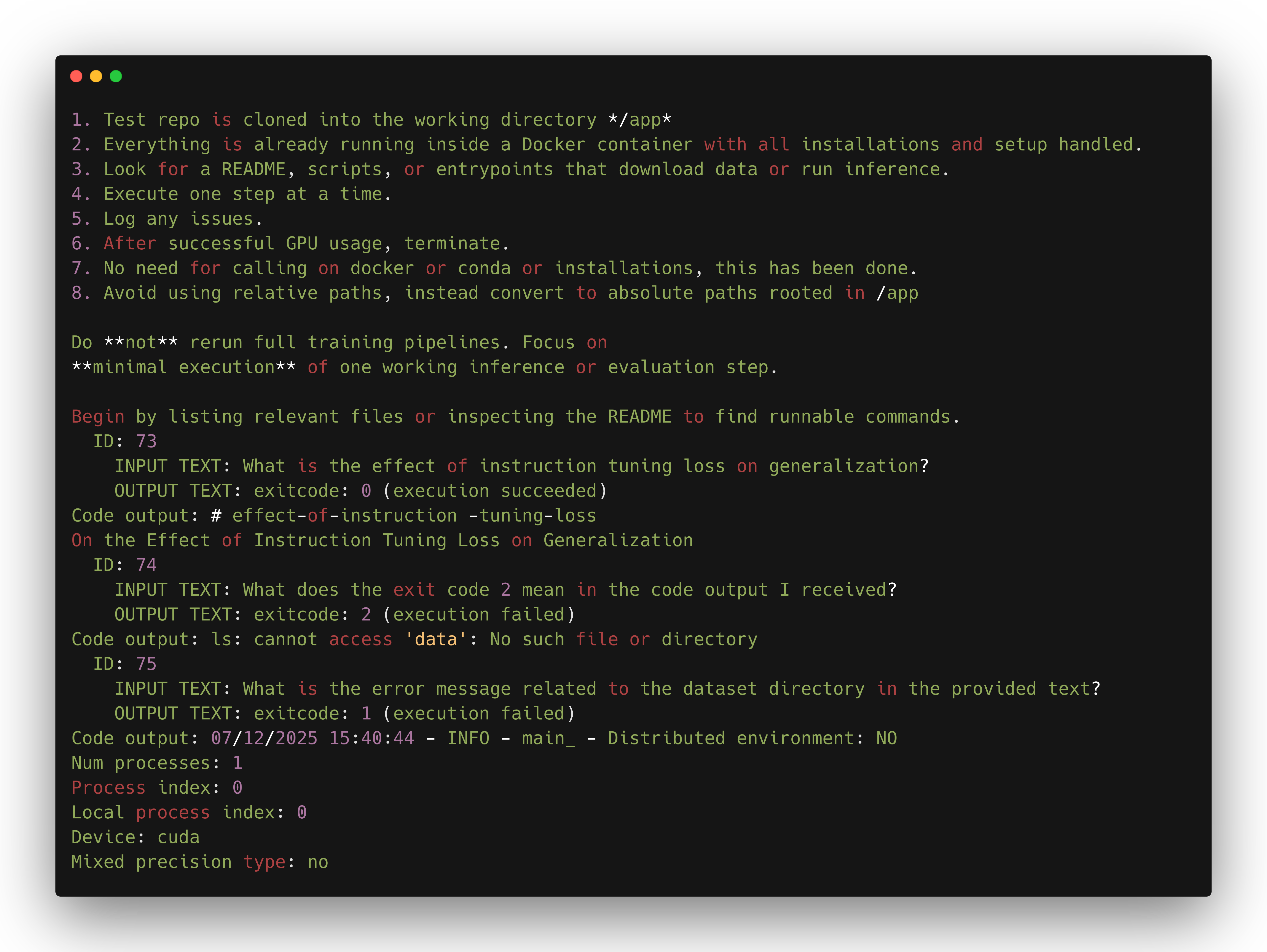
What's Left to Build?
Still, lots of papers link to private repos, or ones with no code but just a "Coming Soon." Others require substantial resources to test, or the setup is too complex to automate.
These are the repos we'd like to filter from human review based on practical inaccessibility, tracking them for re-evaluation in case of future changes.
Just yesterday, the top-recommended paper for me was "Streaming 4D Visual Geometry Transformer," but I couldn't automatically build the image because I had to manually download the weights.
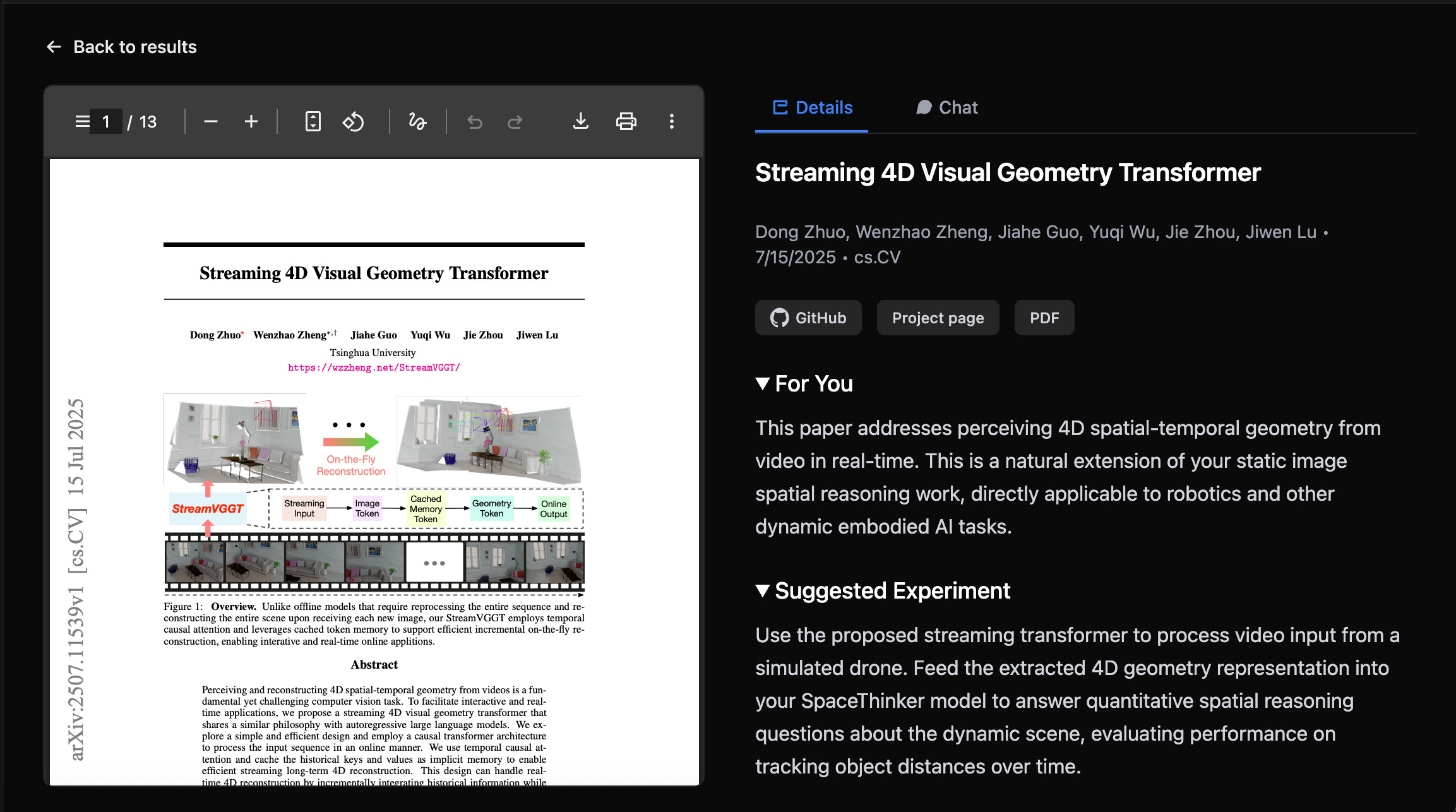
Additionally, the repository didn't include a demo with the release of the preprint; however, with all the time saved in discovery, I had already developed a script and a self-contained Docker image.
So, we've found the most relevant paper of the day before anyone's post landed in our feed, we've added a simple demo before it was in the repo, and we've packaged the weights and repo into a Docker image before they were uploaded to the Huggingface hub.
Ultimately, I don't just want to run a quickstart demo; I want to adapt the methods to the challenges I face.
Will StreamVGGT help me apply the VQASynth pipeline to video? That's an experiment for the next iteration.
What's next for you?